
Interpreting Speech Emotion for the Hearing-Impaired
Introduction
Around 38.2 million Americans have reported some degree of hearing loss last year, which is around 14.3% of the population. I actually fall into this group as well as I was born with slight hearing impairment in my right ear. Luckily, it’s not to the point where it affects my everyday life or ability to work, but I do occasionally feel the impact of mishearing or misunderstanding what other people say. From personal experience, the toughest part in trying to communicate with someone that is hearing-impaired is the initial contact. How do you alert someone that has trouble hearing from far away without running over and tapping their shoulder? If that person is deaf, how do you express the emotion or intent of your words?
In response to this, I thought it would be a great idea to come up with an alerting system prototype that notifies people of the speaker’s gender and emotion.
Contents
- Introduction
- Data
- Audio Analysis
- Convolutional Neural Network
- Results
- Key Takeaways
- Future Considerations
- Link to Presentation
Goals:
- Acquire and process the speech-emotion audio dataset
- Compare models that analyze the features of an audio file
- Use a convolutional neural network to classify speech emotion and speaker gender
- Test the model on new audio files
- Deploy an app that processes an input audio file and returns speech emotion and speaker gender
- Recognize future applications of the analysis such as a more personalized assistive device for the hearing-impaired population
Questions to Answer:
- Can a neural network classify speech gender and emotion?
- Does a neural network outperform other classification models?
Data
I utilized the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) for this project. The audio files were categorized based on emotion, actor, and statement.
The following emotions were used:
- Angry
- Disgust
- Fear
- Happy
- Neutral
- Sad
- Surprise
The actors were of the following genders:
- Male
- Female
The audio file was one of the following statements:
- “Kids are talking by the door”
- “Dogs are sitting by the door”
Audio Analysis
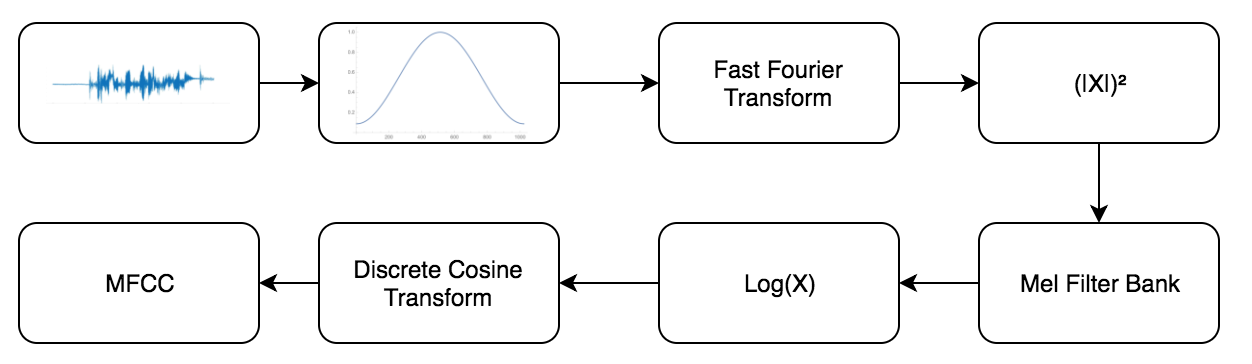
I analyzed the audio files using the librosa package - more specifically I worked with the mel-frequency cepstral coefficient (MFCC). The MFCC is the most widely used acoustic feature for speech recognition and it models the spectral energy distribution in a perceptually meaningful way. The algorithm takes in an input audio file, breaks it down into samples, and processes it through several transformations in order to mimic properties of human hearing.
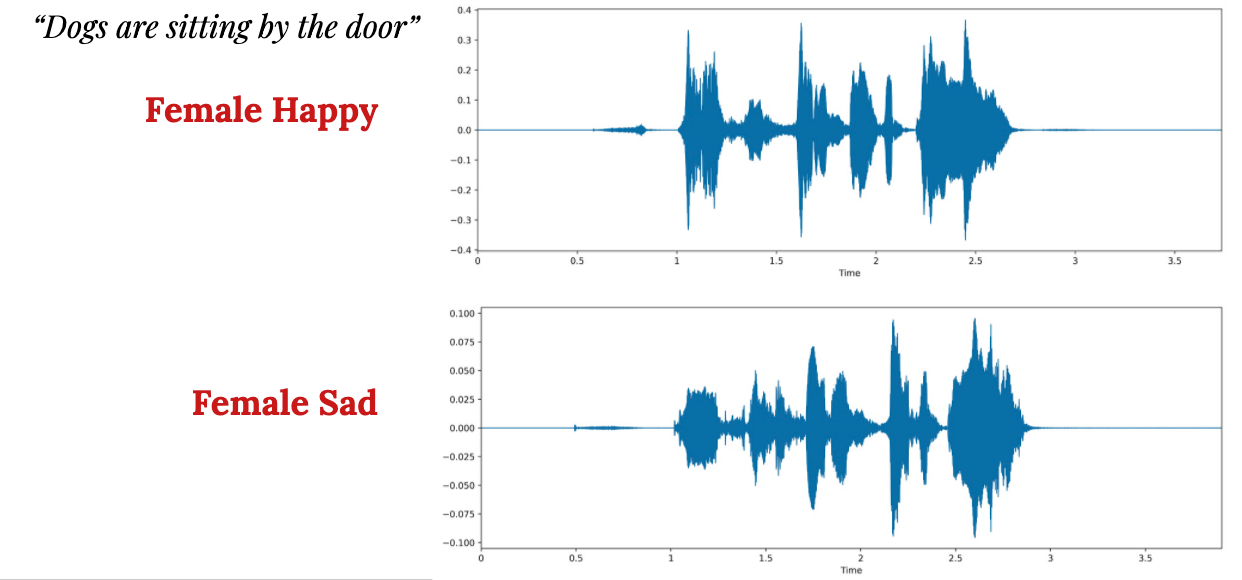
If you look at these examples, you can clearly see that there are differences between a happy sound vs. a sad sound. The MFCC provides the best representation of these differences which then can be converted to vectors. These vectors were then used as features for the target label (gender-emotion) in training a model.
Convolutional Neural Network
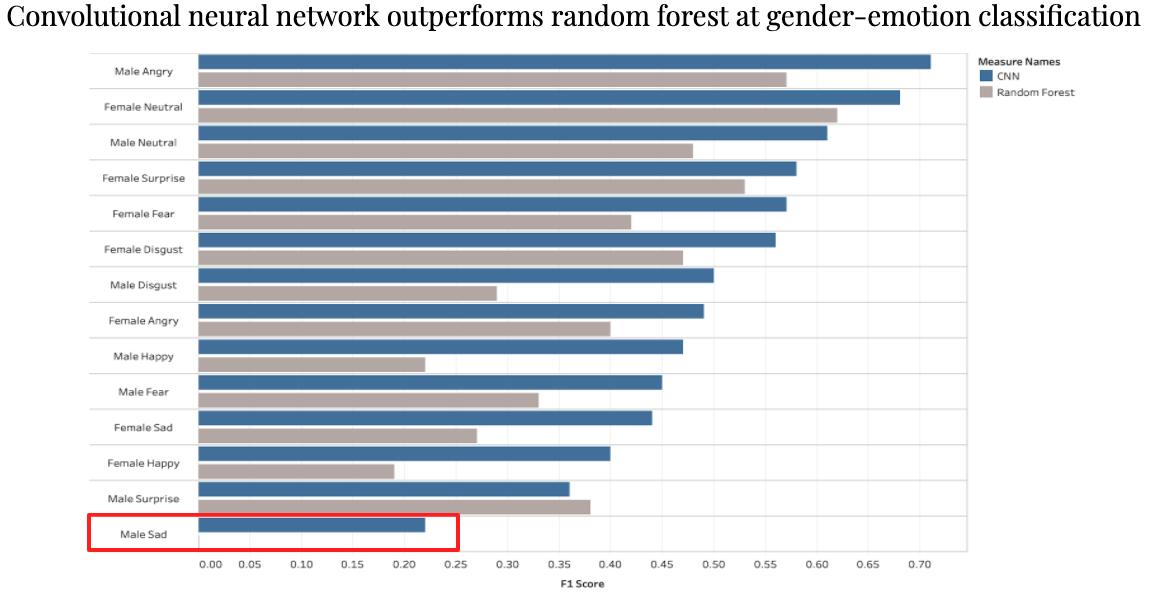
For modeling, I compared a random forest model to a 1-dimensional convolutional neural network to see how well they did in the gender-emotion classification. While CNNs are generally used for image classification, a 1-D CNN is very effective in analyzing data over a fixed period such as audio recordings. The difference in these CNNs is the structure of the input data and how the kernel moves across the data.
As you can see above, the CNN outperformed the random forest at nearly every gender-emotion combination. I chose to show the F1 score here as it shows a balance between precision and recall for model performance. However, across all metrics (accuracy, precision, recall, and F1) the CNN outperformed the random forest.
The predictive power is best highlighted by the Male-Sad target in which the CNN had a 0.23 F1 score compared to a 0 F1 score for the random forest.
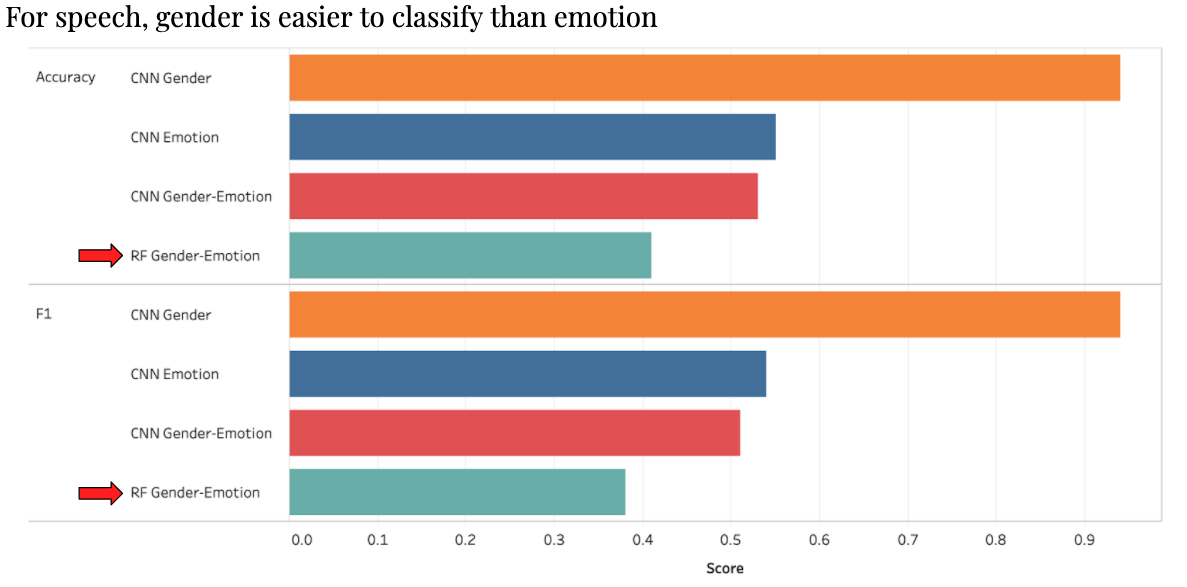
However, I did notice that the CNN model had an accuracy score of only 0.525. Breaking down the model a little more, I found that gender was much easier to classify than emotion. This makes sense as there were more options for emotion and thus more variation and error room for predicting the correct emotion.
As a reference, every CNN breakdown performed better than the random forest base model.
Results

So, can my app be trusted? Well just as a reference, if a hearing impaired person were to blindly guess the correct gender and emotion of a person calling for them, it would be 1/14 or a 7% chance. Comparing this to my model’s 52.5% accuracy, I see the 7 times increase in accuracy as a win.
Streamlit App Demo
Here’s a demo of my deployed app!
Once a user uploads a .wav file of human speech, the app analyzes the audio and gives the gender and emotion of the speaker. Ideally I would have a feature that provides the transcription of the audio file as well, but I could not include it due to Streamlit’s limitations. If you would like to see the code for speech transcription, it is available in the app’s python file here.
This app has been deployed and is available here: https://speech-emotion-interpreter.herokuapp.com
Key Takeaways
-
Extracting human intent is difficult but possible. There are clear nuanes in human speech and it’s hard to create a 1-to-1 translation for computers. This could become even more complicated if we consider different dialects, languages, and accents.
-
However, on a more positive note, these tools can be used to create a more personalized assistive device. Currently, there are general tools that help the hearing-impaired population at large, but implementing personal touches (such as recognizing the user’s name) could help improve their quality of life.
-
Machine learning can help reduce the financial impact of hearing loss. It is estimated by the Better Hearing institute that hearing loss negative impacts household income on average up to $12,000 per year.
-
Personally, I would have loved to have this type of alerting system integrated into my phone or watch as I was growing up. Often times people would have to call my name several times to get my attention and an app like this would have definitely helped. This product doesn’t just have to be restricted to the hearing-impaired population. For example, I can envision it being used for when people are listening to loud music on their earphones. My app is meant to be used as a supplementary tool and hopefully it can help improve the quality of life for those that need it.
Future Considerations and Applications
Considerations
- Create separate neural nets for gender and emotion to see if this would help increase the overall accuracy score.
- Utilize additional audio datasets so that the model can have improved training.
Surrey Audio-Visual Expressed Emotion (SAVEE), Toronto emotional speech set (TESS), Crowd-sourced Emotional Mutimodal Actors Dataset (CREMA-D)
Applications
- Incoporates the gender-emotion analysis into a tech product (i.e. Apple Watch, Fitbit). Speech transcription would also be a great complement to this project as this could significantly improve communication for the hearing-impaired.
- Include haptic feedback, in which the product vibrates in response to the user’s name and also tells you the speakers gender and the speech emotion.