
Creating a Chopped Mystery Basket Generator and Ingredient Recommender
Introduction
Chopped is a cooking series on the Food Network program that invites four chefs to come and cook dishes based on the ingredients in a mystery basket. There are three rounds (appetizer, entree, dessert) and one chef is eliminated each round based on the judges’ decision. What makes this show really interesting is that the mystery baskets have ingredients that you would think are impossible to combine to make an edible dish. However, Food Network has revealed that there is actually a culinary department that predetermines these baskets, which are just hard enough for the contestants.
“They don’t want to make a basket that’s impossible, just incredibly difficult.”
-Ted Allen, host of Chopped

This effort is probably why the show is so fun to watch and perhaps even intense. Given the seemingly random nature of these mystery baskets, I wanted to see if it was possible to draw out some pattern in the ingredients by clustering them. With those clusters, I decided to make my own Chopped basket recommender using all the ingredients that have ever appeared on the show so far.
Contents
- Introduction
- Data
- Word Embedding
- Clustering
- Results
- Key Takeaways
- Future Considerations
- Link to Presentation
Goals:
- Use word embedding to convert each individual ingredient into vectors
Word2vec
- Select a clustering model that will group the ingredients for labeling:
k-means clustering, hierarchical clustering
- Understand the importance of human intuition for food relationships
- Deploy an app that generates a Chopped Mystery Basket
Questions to Answer:
- Are there specific food groups that make up the Chopped Mystery Basket? Or is it just a random set of ingredients?
- Can food and its relationship to other foods be accurately captured by machine learning algorithms?
- Can the Chopped Mystery Baskets be recreated using machine learning?
Data
I utilized the above dataset from Kaggle, which contained the details of every Chopped episode for the past ten years. From this, I used the information for the appetizer, entree, and dessert baskets and pulled the individual ingredients out from there using natural language processing (NLP).
Word Embedding
Word embedding is a natural language processing technique that maps text to vectors. This representation allows us to derive relational value between words. Given that the “documents” in my corpus were just single ingredients, it made sense to use word embeddings to vectorize each word. This was done through transfer learning: a gensim model was trained utilizing Google’s Word2vec. Essentially, I borrowed the pre-trained set of word embeddings from Google and applied it to my own model.
Google’s model can be downloaded from the link below. Just note that this will require ~4GB of RAM to fit in memory. https://drive.google.com/file/d/0B7XkCwpI5KDYNlNUTTlSS21pQmM/edit
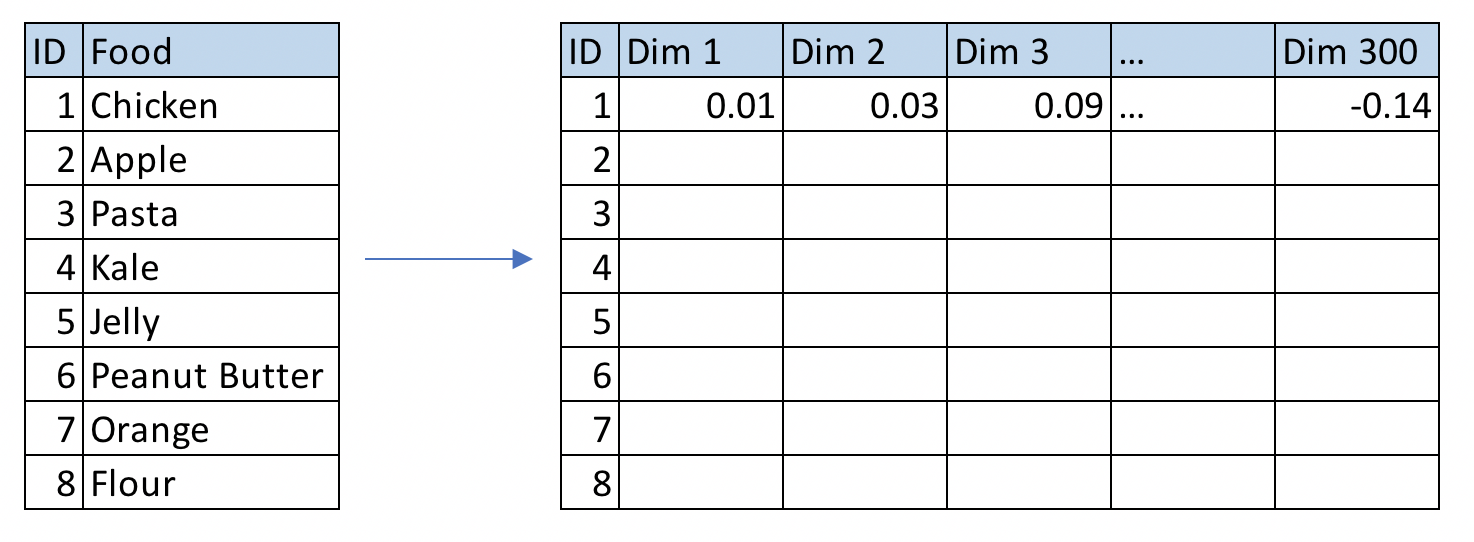
For my project, Word2vec put each ingredient into a 300-dimensional space (a vector that has 300 values) and this allowed me to get some type of meaning/relationship between the ingredients. By utilizing this model, you can see which words are most similar to each other. This idea was used for my similar ingredient recommender, which is explained below.
Clustering
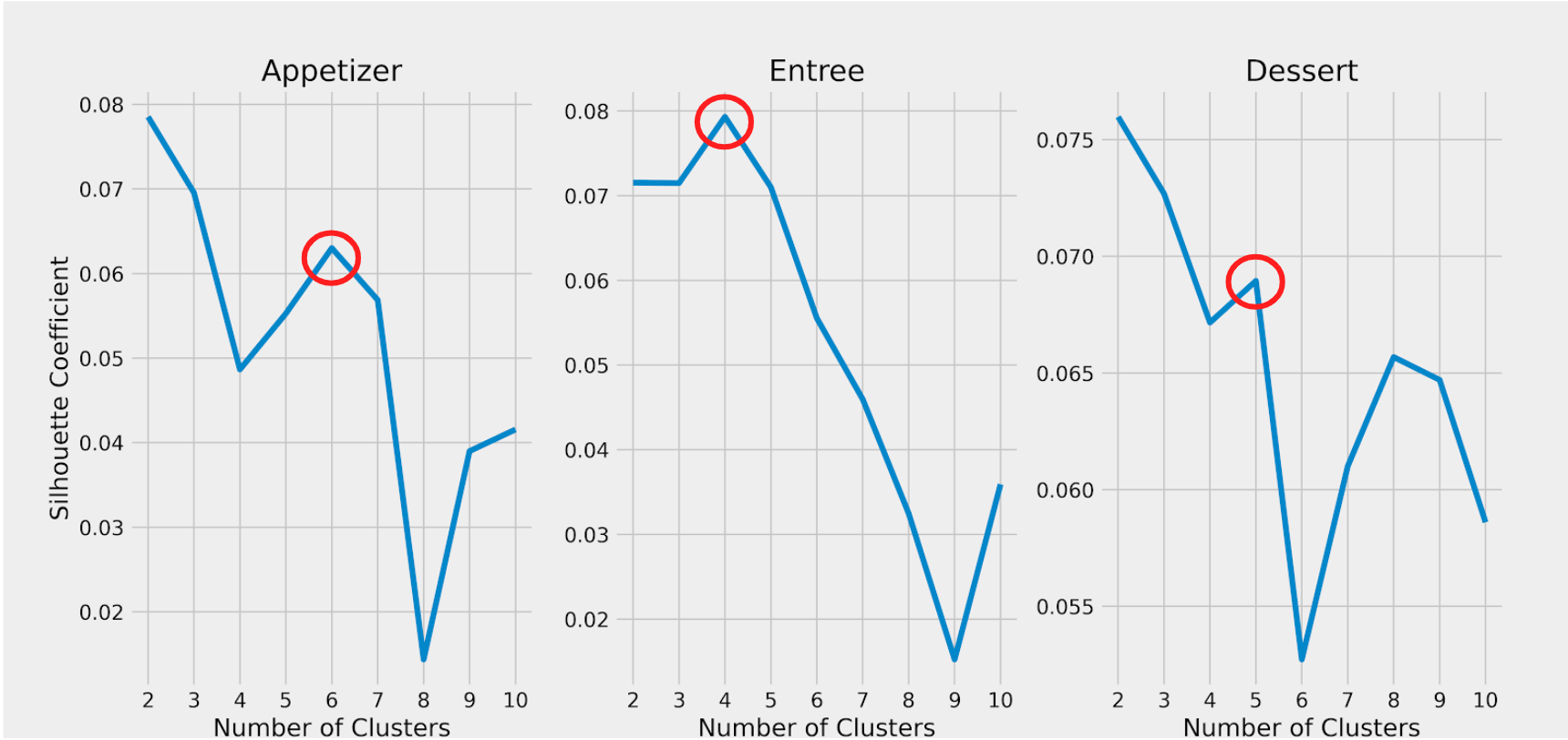
After comparing k-means clustering with a few hierarchical clustering models, I ended up using k-means. Within this model, I found the optimal k by using the silhouette score. This was done separately for appetizer, entree, and dessert, which resulted in a different optimal cluster number for each round type.
Results
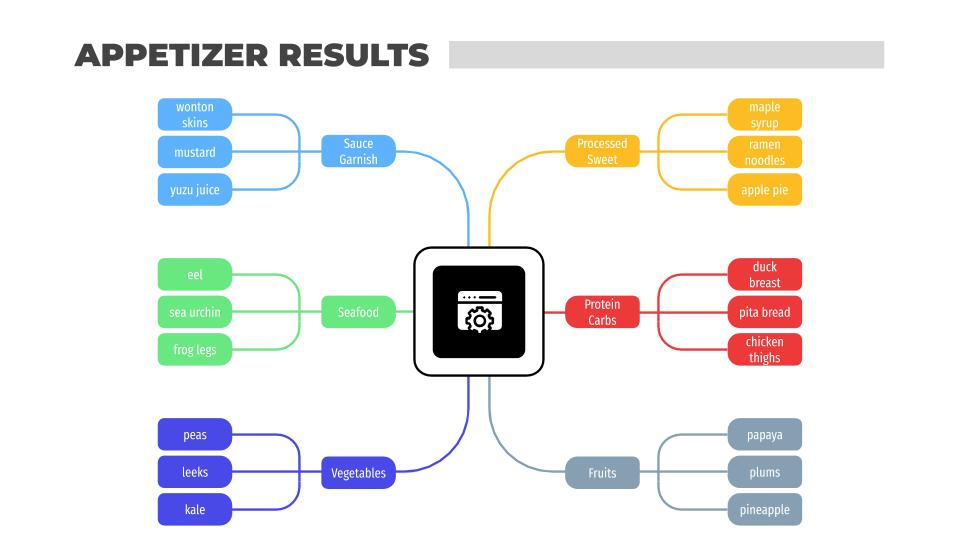
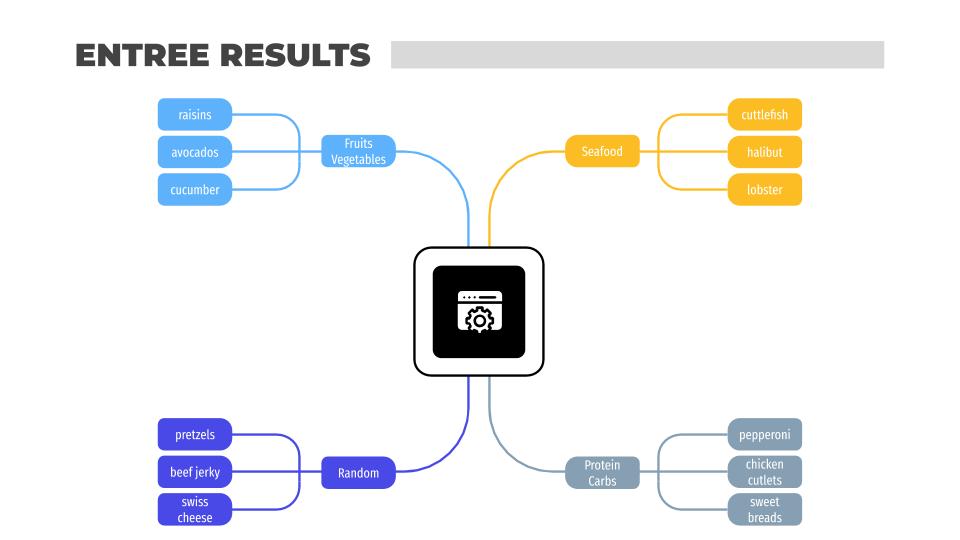
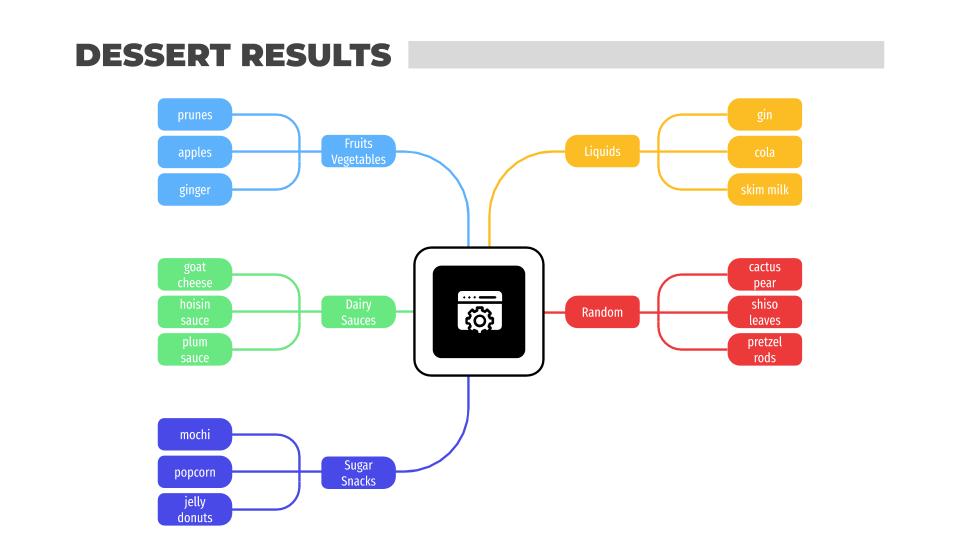
This is a snapshot of the results for each round type. Obviously there are more than three ingredients per cluster but as you can see, there were some clear patterns in each group.
The appetizer round resulted in six clusters:
- Sauce / Garnish
- Processed / Sweets
- Seafood
- Protein / Carbs
- Vegetables
- Fruits
The entree round resulted in four clusters:
- Fruits / Vegetables
- Seafood
- Random
- Protein / Carbs
The dessert round result in five clusters:
- Fruits / Vegetables
- Liquids
- Dairy / Sauces
- Random
- Sugar / Snacks
Streamlit App Demo
Using this data, I deployed a Streamlit app that takes in user input for each round. Here you can see that the user is able to select the types of food they want to include in their basket. Then, the generator creates a basket of four random ingredients from the selected clusters/food groups.
You can also see towards the bottom that there is a similar ingredient recommender. Based on the randomly generated baskets, it suggests the three most-similar ingredients per ingredient. This relationship between foods is pulled from the Word2vec matrix that utilizes a cosine similarity metric. So in case you don’t have a particular ingredient in your kitchen, the recommender shows you some possible alternatives.
One thing to note is that the basket will always consist of four ingredients (like the show) no matter how many food types you select.
This app has been deployed and is also available here: https://chopped-basket-generator.herokuapp.com/
Key Takeaways
-
The Chopped Mystery Baskets pulled from clear food categories. Examples like seafood, vegetables, and fruits were often included in each round.
-
However, just because the food type was available, this did not mean that it was required to be included in the basket. This was demonstrated by the appetizer and dessert baskets, in which there were a greater number of clusters/food-types than the number of ingredients used in each basket (usually four) for the show.
-
Last but not least, human intuition and expertise are clearly needed to organize a challenging but doable episode. It is clear why Food Network has culinary experts working on creating these baskets - the work that a machine can do is somewhat limited in terms of determining the relationship between foods.
Future Considerations
- Get single-type clusters by adjusting k. Some groups seemed to be a mix of two clear food types so maybe more clusters are needed to comb those out.
- Refine model to account for outliers. For example kiwi was in sauce/garnish instead of fruit.
- Expand the base dataset for the similar ingredient recommender. This would provide a larger variety of recommendations.